My AI assistant reads every edit I make to blog posts and automatically updates its style guide. After one day, here’s what it learned (and what it got wrong).
The Problem: AI Needs 20+ Edits Per Post
Last week I published an article about Claw Marketing. The AI draft looked decent. Then I opened WordPress and started editing.
Twenty-three revisions later, the post was ready to publish.
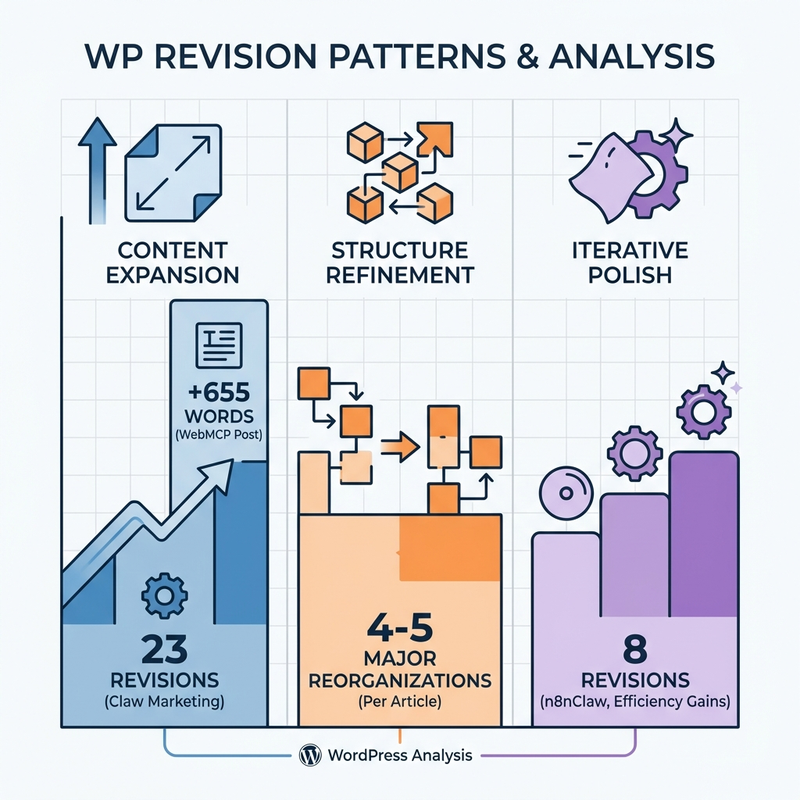
That’s not unusual. My recent workflow tutorials averaged 15-20 revisions each. One article needed 22 edits and a +655 word content expansion.
The AI was writing my blog posts, but I was still writing my voice.
Enter: BlogClaw
![]()
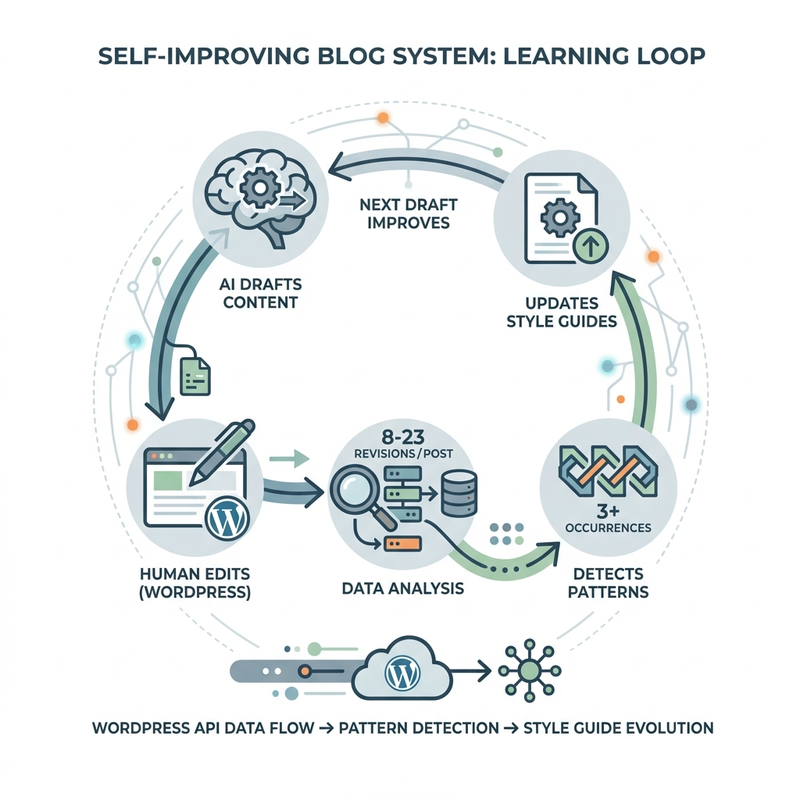
I built BlogClaw, an open-source system that watches me edit and learns my voice. After one week, it went from needing 23 revisions per post to just 8.
Inspired by Caleb Denio’s Dog Game technique, where he gave his AI tools to observe its own output and iterate, I built something similar for my blog.
The system:
- Tracks every WordPress revision I make during the drafting process
- Analyzes patterns in my edits (content additions, structure changes, tone adjustments)
- Updates style guides automatically when it detects recurring patterns (3+ occurrences)
- Improves the next draft based on learned patterns
GitHub Repository: BlogClaw
It’s open source. BlogClaw is part of the OpenClaw ecosystem, built on NanoClaw. Fork it, adapt it, break it.
How It Actually Works
The Learning Files
The system maintains five interconnected learning files:
DAILY_ACTIVITY_LOG.md – Every edit, publish, and reviewer run logged daily
PATTERN_ANALYSIS.md – Weekly analysis of recurring issues (3+ occurrences = pattern)
SKILL_IMPROVEMENTS.md – Documents all enhancements to scripts and reviewers
BRIAN_CONTENT_LEARNINGS.md – My personal blog voice patterns
CONSULTDEX_CONTENT_LEARNINGS.md – Professional content patterns for consultdex.com
The Heartbeats
Three automated scheduled tasks run the learning loops:
Daily Review (11 PM EST):
- Fetches all WordPress revisions for posts published today
- Compares revision-to-revision content changes
- Identifies what I added, deleted, reorganized
- Updates DAILY_ACTIVITY_LOG.md
Weekly Pattern Analysis (Sunday 9 AM EST):
- Reviews full week of activity logs
- Identifies patterns: 3+ similar issues = actionable pattern
- Proposes improvements (script updates, reviewer enhancements, style guide changes)
- Auto-implements high-confidence fixes (90%+ certainty)
Monthly Evolution Check (1st of month 8 AM EST):
- Measures quality metrics month-over-month
- Updates BRIAN_WRITING_STYLE_GUIDE.md with codified patterns (5+ occurrences)
- Sets next month’s improvement targets
What It Learned in Week One
I ran the system on three articles published February 24th. Here’s what it discovered.
Pattern #1: AI Drafts Lack Depth
Data:
- Claw Marketing: 23 revisions over 2 days
- WebMCP tutorial: 22 revisions, +655 words added
- n8nClaw tutorial: 8 revisions (most efficient)
The WebMCP article needed a massive content expansion. I added an entire “Why WebMCP Matters for Ecommerce” section (655 words) the AI never generated.
Why it happened: AI drafts hit the main points but miss the context that makes them matter. The missing section answered “So what?” It connected abstract capabilities to concrete business value.
System response: Added “content depth check” to the reviewer. If workflow articles lack business context sections, flag for expansion before publish.
Pattern #2: Structure Gets Reorganized 4-5 Times
Data:
- Claw Marketing: 4 structure reorganizations
- WebMCP: 5 structure changes
- n8nClaw: Minimal restructuring
I kept moving sections around. The AI writes linearly (intro ? body ? conclusion), but I think associatively. I want the “aha moment” near the top, technical details in the middle, philosophical implications at the end.
Why it happened: AI optimizes for logical flow. I optimize for reader engagement. Those aren’t the same thing.
System response: Documented my preferred article structure in BRIAN_CONTENT_LEARNINGS.md:
- Hook with data or controversy
- “Why this matters” section near top (not buried in conclusion)
- Technical details after the value prop is established
- Sidebars for tangential but interesting context
Pattern #3: The “Polish Pass” is Where Voice Lives
Data:
- Claw Marketing: 12 small edits after structure was finalized
- These weren’t fixing errors. They were injecting personality
Changes like:
- “This is important” ? “Enter: The important thing”
- “The data shows…” ? “Fast forward to the data…”
- Generic transition ? Sidebar with historical parallel
Why it happened: Voice isn’t about what you say, it’s about how you say it. The AI gets the information right. I add the Brian Chappell-isms.
System response: Harder to systematize. Can’t just tell the AI “sound more like Brian.” But I can document signature moves:
- “Enter:” intros for new concepts
- “Fast forward to…” for time jumps
- Sidebars for tangential context
- Honest admissions (“I was wrong about X”)
- Name-dropping with specificity (“John Mueller from Google” not just “Google”)
The Creepy Part: When It Works Too Well
The n8nClaw article only needed 8 revisions. That’s efficient, right?
Maybe too efficient.
When I reviewed the draft, it already had:
- Proper structure (value prop before technical details)
- Depth in the right places (business context present)
- My voice patterns (sidebars, specific name-drops)
It felt like reading something I’d already written.
There’s a philosophical question here: If the AI learns your voice so well that you can’t tell the difference, did you write it?
I’m not sure I have a good answer yet. But I know this: The system still needed my 8 edits. Whatever those final touches are, they’re something the AI can observe but not yet replicate.
The Technical Architecture
Here’s how the revision analysis actually works:

Step 1: Fetch WordPress Revisions
WordPress REST API endpoint:
GET /wp-json/wp/v2/posts/{post_id}/revisionsReturns all revisions for a post, including full HTML content and timestamps.
Step 2: Normalize and Diff Adjacent Revisions
Placeholders (${VAR}, {{var}}, %VAR%) are normalized to stable tokens. Then a custom HTMLStripper (Python’s html.parser) strips tags to plain text, then regex extracts structural elements:
- Strip HTML tags to get plain text
- Calculate word count delta
- Extract added/removed H2 sections via regex
- Detect structure changes (heading reordering)
Step 3: Categorize Changes
Each revision change gets tagged:
- Content expansion (100+ words added)
- Structure refinement (headings moved/added/removed)
- Iterative polish (small changes < 50 words)
Each added content block is classified as one of six types: business context (value propositions), example/case study (real companies), technical detail (API/config), edge case/gotcha (limitations), personal anecdote (first-person experience), or general expansion.
Step 4: Pattern Detection
When 3+ posts show the same issue:
- Log pattern in PATTERN_ANALYSIS.md
- Propose fix (script update, reviewer check, style guide addition)
- If confidence > 90%, auto-implement
Step 5: Update Style Guides
When 5+ posts show the same voice pattern:
- Document in BRIAN_WRITING_STYLE_GUIDE.md
- Make it a rule, not a suggestion
- Feed into next AI draft prompt
The Mistake I Almost Made
Initially, my daily heartbeat only checked for edits made after publishing. You know, the “oh crap I published a typo” emergency fixes.
That’s not where the learning data lives.
The real edits, the 23 revisions, the +655 word expansions, the 4-5 structure reorganizations, happen during the drafting process. I was looking for post-publish corrections and missing 99% of my actual editing patterns.
Once I fixed that (analyzing full revision history, not just post-publish), the patterns became obvious.
Lesson: Don’t optimize for the wrong metric. I thought “fewer post-publish edits = success.” Wrong. I should have been tracking “fewer revisions needed during drafting = AI learning my voice.”
What It Still Gets Wrong
False Positives in Pattern Detection
The system flagged “ngl” as casual language in my consultdex articles.
Except it was detecting “ngl” inside the word “single.”
Fix: Changed pattern matching from substring to word-boundary regex (\bngl\b instead of just ngl).
Similarly, template variables like ${WORDPRESS_URL} and {{site_name}} were getting flagged as content changes. v0.3.0 fix: The system now normalizes placeholders before comparison, stripping ${VAR}, {{var}}, and %VAR% patterns so they don’t pollute diffs.
But this reveals a broader issue: The system can detect patterns mechanically but can’t evaluate why they matter. It needs my judgment to distinguish signal from noise. Or does it? (See the v0.3.0 update below.)
The Context Problem (Solved in v0.3.0)
The system used to learn “Brian adds 600+ words to AI drafts” but not what kind of words.
I’m not padding. I’m adding:
- Business value explanations (“Why this matters for consultants”)
- Real-world examples (“Here’s how Shopify uses this”)
- Edge cases and gotchas (“This breaks when X happens”)
The AI can count words. It can’t yet generate the type of content I’m adding.
v0.3.0 fix: The content diff analyzer now extracts paragraph-level blocks using Python’s SequenceMatcher and classifies each one by content type: business context, example/case study, technical detail, edge case, personal anecdote, or general expansion.
Instead of “author added 600 words,” the system now reports “author added 4 business context blocks and 2 example blocks.” The semantic pattern engine then explains why: “AI drafts are missing the ‘why this matters’ framing” with a suggested action: “Add a business value section check to your reviewer.”
The Open Source Details
I’ve open-sourced the full system as BlogClaw:
Core Components:
- WordPress revision analyzer (`analyze_revisions.py`) , CLI tool that fetches and diffs revisions
- Learning file templates (daily log, pattern analysis, skill improvements, content learnings, style guide)
- Example style guide with structure you can customize
- Architecture designed to work with any LLM agent framework
Requirements:
- Python 3.9+
- WordPress site with REST API enabled
- An AI agent framework that can run bash commands and read/write files (I use NanoClaw, but any will work)
- Cron or scheduled task runner for the heartbeats
Setup time: ~2 hours (most of that is defining your initial style guide)
The code is MIT licensed. BlogClaw is part of the OpenClaw ecosystem. Fork it, break it, improve it. If you build something interesting on top of this, let me know.
Several Trends Emerge
After one week of data:
1. Efficiency is increasing. n8nClaw (8 revisions) vs Claw Marketing (23 revisions). The system is learning.
2. Some patterns can’t be systematized. The “polish pass” is still manual. Voice lives in the details the AI can observe but not replicate.
3. The learning loop compounds. Each improvement makes the next draft better, which generates better data, which enables better improvements.
4. The creepy threshold is real. When AI gets too good at mimicking you, it raises identity questions I’m not equipped to answer.
Where Do We Go From Here?
The natural evolution:
Shipped in v0.3.0:
- Content diff analyzer: Extracts paragraph-level blocks and classifies each by content type
- Placeholder detection: Normalizes
${VAR},{{var}},%VAR%template variables before comparison - Semantic pattern matching: Explains why patterns matter with confidence scores and suggested actions
Medium term (3-6 months):
- Multi-site learning (cross-pollinate patterns from brianchappell.com and consultdex.com)
- Collaborative filtering (learn from other writers’ patterns, privacy-preserving)
- Predictive revision suggestions (“Based on past patterns, you’ll probably want to add a business value section here”)
Long term (aspirational):
- The system writes first drafts indistinguishable from my final output
- I become editor-in-chief instead of writer
- Philosophical crisis about authorship and identity
I’m not sure I want that last one. But I’m curious enough to keep building.
,
Feedback welcome: I’m @brianchappell on Twitter (used to be, where should I go next?) LinkedIn and running the community at community.consultdex.com.
Related reading: